Uncategorized
Fixing Windows 10 non-responsive start menu Marcel de Vries 17 Mar, 2016





Since C# 8, developers can opt-in to use Nullable Reference Types (NRTs). With NRTs, developers get a set of ‘tools’ to avoid the most common exception: the NullReferenceException. These tools include the nullable annotations, attributes, warnings, and static code analysis. Starting from .NET 6, NRTs are enabled by default when creating a new project. You can always opt-out if you want, but -to be honest- I think you shouldn’t!
And even though NRTs have existed for some time, I still find a lot of people are hesitant about adopting it. Maybe unknown is unloved? I strongly believe that fully embracing NRTs results in better, more understandable, and more robust code! Let me show you what I mean by that and how you can start using NRTs.
One of the main reasons NRTs are great, is because it gives a lot more meaning to your code. It makes code less ambiguous, more understandable.
Being able to explicitly indicate that a value type is nullable or not, is something we are so accustomed to. The intent of using a value type is clear: there will always be a value to expect or to provide, they cannot be null. Nullable value types, on the other hand, can be used in scenarios where it is perfectly legitimate that a value might be null, that a value is optional; there are use cases where it makes sense not to have a value.
Thanks to Tony Hoare ‘s “The billion dollar mistake” (https://en.wikipedia.org/wiki/Tony_Hoare), reference types can be null. What’s even worse is the fact that in .NET values of reference types are null by default and -prior to C# 8- there wasn’t any way to indicate that an instance of a reference type should not be null. We used to have Code Contracts in earlier versions of .NET, which could help with defining what should be nullable and what not. But Code Contracts are end of life and are being superseded with NRTs. The most common way developers deal with nullability, is by doing null checks where they wouldn’t want to have null values and throw an Exception. The downside? These are runtime checks! If a developer passes a null value where it isn’t expected, it’s not known until runtime that it isn’t allowed.
The following snippet shows a method signature which, when not using NRTs, has many uncertainties:
![]()
Is it possible to pass a null value as search criteria if I want the entire list of items? Can I pass null as SortParams if I don’t want my search result to be sorted? If we don’t find anything, I’ll get back an empty list, right? Or will the result be null?
By looking at the method signature, we just don’t know. We don’t know for sure what the intent of this method and its parameters are, or what the intent of the developer was. Oh, and did you notice this method is virtual? Another class inheriting this class, might override this method and could possibly handle the parameters and return type entirely differently. Not to mention that this is considered a bad practice as it clearly violates the Liskov Substitution principle.
When not using NRTs, there is no way – like with (nullable) value types – to express the intent. Is it allowed to pass a null value to a certain method? Will a value returned by a method always have a value, or should I do a null-check? Because the platform doesn’t force us to think about nullability, developers tend to not really think about it. The result? Firstly: NullReferenceExceptions! Secondly: lots of code where the intent is not always clear.
Having NRTs forces you to take nullability into account! It makes your code a lot more self-describing: it’s all about expressing intents and defining what’s expected, what’s possible and what’s not.
When working with NRTs, the above Search method becomes a lot more unambiguous:
![]()
Both arguments can be nullable, and we rest assured we’ll never get back a null value from this method. Just like that, by looking at the method signature, we can immediately identify its intended use.
Since C# 8 we can enable a nullable annotations context in order to use NRTs. With NRTs, developers need to explicitly indicate whether a value of a reference type can be null, as they are non-nullable by default. Enabling NRTs for your entire project can be done by adding the following to your csproj file:
![]()
You could also choose to enable or disable NRTs on a file basis, by using the following directives:
Or
Once enabled, a nullable reference type can be defined by adding a ‘?’ to the declaration, in analogy with value types:

Unlike with nullable value types, we are not changing the underlying type by adding a ‘?’: both ‘string’ and ‘string?’ refer to the System.String class. The compiler will keep track of the nullable annotation, but the type itself doesn’t change! With this extra information, the compiler can do very interesting and helpful code analysis. Take a look at the following listing:

See how immediately the compiler starts to give us warnings. The text variable is nullable, so we should do a null-check prior to calling a method on it, unlike with text2 which is non-nullable. But because text2 is non-nullable, we do get a warning when assigning null to it.
Don’t ignore the warnings
Way too often, I see that warnings are being ignored by developers. I, personally, always enable ‘Treat Warnings As Errors’ on the projects I’m working on. Enabling NRTs without making sure all related warnings are resolved, doesn’t make much sense to me. Not everybody wants to treat warnings as errors, but did you know you can tell the compiler to only treat NRT-related warnings as errors? Adding this to you csproj does just that: <WarningsAsErrors>nullable</WarningsAsErrors>
When enabling NRTs, you really should have this set as a minimum! It forces developers to really focus on dealing with all the aspects of NRTs.
Ideally, you should enable ‘Treat Warnings As Errors’ in your (future) projects!
Let’s fix the above warning by adding an explicit null-check:

Notice that the error we had previously on the text variable is now gone!
The compiler will constantly track a variable’s null-state. In Visual Studio, we can consult the inferred null-state by hoovering over the variables. The tooltip will say whether a variable may be null or not null at a given place. Now, take a look at the following:

No warning. And if we would hover over the text variable after the first if, the tooltip would say the text variable is not null here. How does the compiler know that? We don’t do an explicit null check, but still the analyzer infers the variable’s null state after calling the IsNullOrWhiteSpace method.
The answer is:
There are a handful of attributes that we can use to help the compiler figuring out the null state of variables. Let’s look at the IsNullOrWhiteSpace method of the String class that we used in the code above:
![]()
The NotNullWhen attribute can be used to tell the compiler that the given argument, which is nullable, will be not null when the method returns the specified bool value (false in this case). It is because of this attribute that, in our previous example, the compiler was able to determine that text is not null inside that if-block as we would only enter that if-block when the IsNullOrWhiteSpace method returns false. All those attributes that help the compiler infer the null state of variables can be divided in different categories.
Attributes in this category let the compiler infer the null state of a variable based on the return value of that method. Just like the NotNullWhen attribute we just discussed. Another example of such an attribute in this category is the MaybeNullWhen attribute. This one is typically used for Try-methods, like the IDictionary’s TryGetValue method for example:
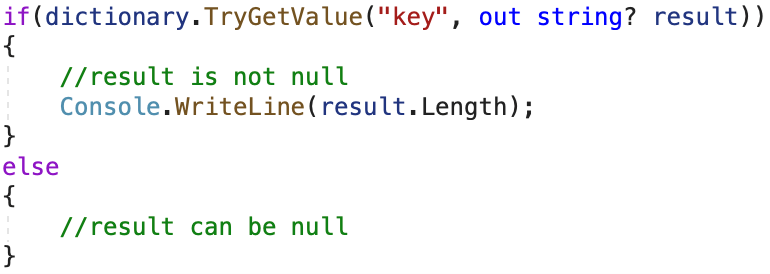
Although we’re passing in a nullable string value as out parameter, inside the if-block, the compiler doesn’t warn us about the result value potentially being null. That is because the definition of the TryGetValue looks like this:
![]()
Because of the MayBeNullWhen attribute, the compiler knows that the out value can only be null when the method returns false. Hence, in the above example, we don’t get a warning when accessing the Length property on the result variable when the TryGetValue method has returned true. Another attribute in this category is the NotNullWhenNotNull attribute. An example of this attribute can be found in the Path’s GetFileName method:

This attribute tells the compiler that the return value will not be null if the provided parameter is not null. Let’s see this in action:

Because of the null-check on the path variable prior to passing it to the GetFileName method, the compiler infers that the resulting filename variable is not null, thanks to the NotNullIfNotNull attribute.
These attributes are used on classes and methods in the BCL starting from .NET 3.0 and .NET Standard 2.1. Can you use NRTs in .NET Standard versions prior to 2.1? Yes! But methods and classes won’t have these attributes on them to help the compiler to infer null state, so you will have to do additional null-checks yourself if you want to get rid of all warnings.
The previous examples showed examples of attributes on baked-in methods and types in the BCL. We can, of course, add these attributes to our own methods as well. Interestingly, when applying these attributes, you will get warnings when the implementation of the method doesn’t match with the attribute defined. Take a look at following snippet, which is a good example of using the NotNullIfNotNull attribute:
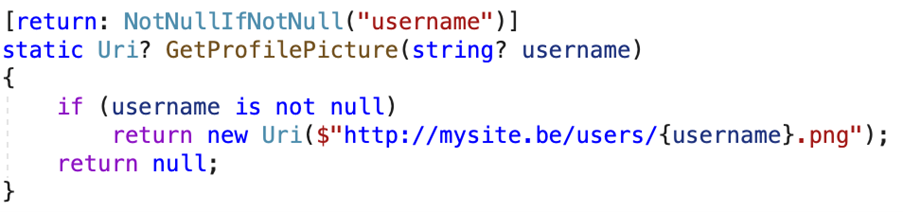
If I would have made a typo, and typed ‘is null’, instead of ‘is not null’, I’d get a warning:

The warning says: “Return value must be non-null because parameter ‘username’ is non-null.” With this typo, the implementation of this method wouldn’t match what the NotNullOfNotNull attribute describes.
This category of attributes informs the compiler about the null state of a value after the method completes successfully. The NotNull attribute is typically used on nullable method parameters in scenarios where we want to inform the compiler that the value of the parameter is not null when the method exits successfully. For example, we could rewrite the GetProfilePicture method we had before, so that it throws an exception when the given username parameter is null:
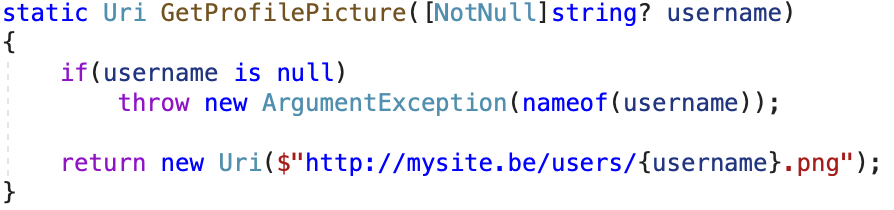
Because of the NotNull attribute, the compiler will know that the username variable will not be null when the method completes successfully.
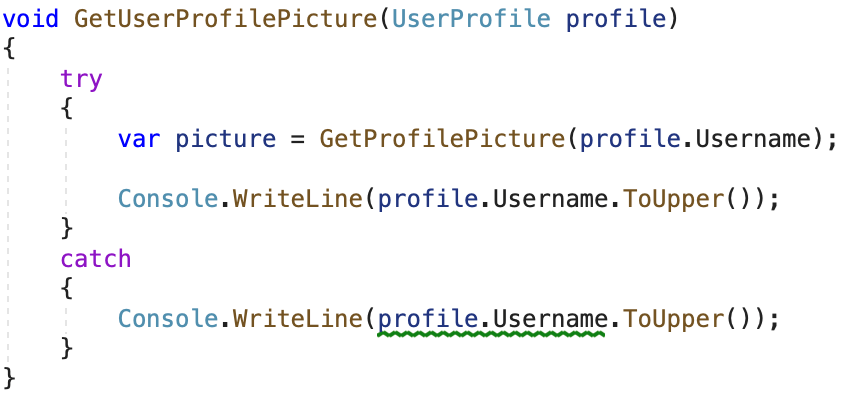
The listing above shows that in the catch-block the compiler warns us about the fact that the Username can be null. We should do a null-check before accessing it. In the try-block, on the other hand, after successfully calling the GetProfilePicture method, the compiler doesn’t warn us because, at that point, we know the value of Username is not going to be null.
As you might expect, the MaybeNull attribute can be declared on a non-nullable parameter that is passed to a method by reference, which might be null when the method returns. Also, prior to C#9, the MaybeNull attribute was used a lot in combination with generics. In C#8 it isn’t possible for an unconstraint generic type to be marked as nullable. Because of that, the only option to mark that an unconstraint generic return value could be null was by using the MayBeNull attribute.
In my personal experience, I don’t use the MaybeNull attribute often. Instead of adding the attribute, I can just make the return type of a method nullable, which I can now do for every type since C#9 supports nullable unconstraint generics.
Besides Conditional Post-Condition and Postcondition, there are attributes that form the Precondition category. With these attributes, we can assign a value that doesn’t match the nullable annotation of that variable.
Imagine a UserProfile class that has a Bio property. We want the bio property to be non-nullable, but the backing field, on the other hand, might be nullable (this could, for example, be the value that is persisted in the database). When the backing field is null, the Bio property returns a default value. Because the Bio property is not nullable, we cannot assign null to it without getting a warning. But on the other hand, we might want to be able to ‘reset’ the user’s bio, so we actually want to be able to assign a null value to the Bio property. This can be easily achieved by adding an AllowNull attribute:

This allows us to assign a null value to the Bio property, whilst being assured we’ll never get back a null value from it:

The DisallowNull attribute is the same but different. Its purpose is to disallow assigning a null value to a nullable property. For example, a Product class can have a Rating property which is nullable, i.e. a product may not have a rating yet, but once it has a rating, it cannot be removed, it can only be updated.

With the DisallowNull attribute, we can have a property that can be null, but from code, we are not allowed to assign a null value to it:

Another pair of interesting attributes are the DoesNotReturn and DoesNotReturnIf attributes. Their purpose is to inform the compiler about unreachable code. They are particularity useful on Exception helper methods. Take a look at the following example:
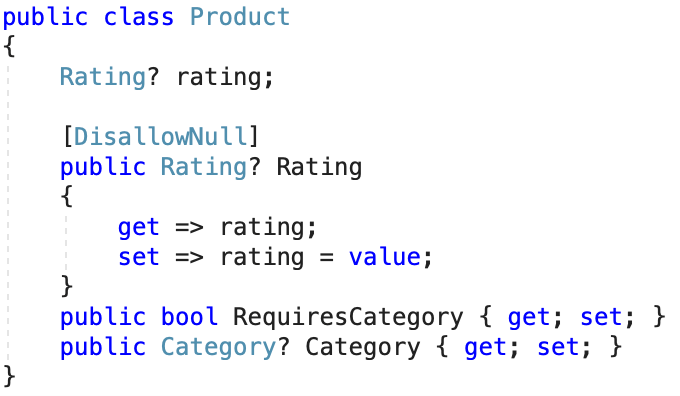


See how, under the if-block, we don’t get a warning when accessing the Category property. That’s because we do a null check and the ThrowUnexpectedValueException method is marked with a DoesNotReturn attribute. Hence, the analyzer can perfectly determine there is no other way we can reach the code below the if-block other than when the Category property is not null.
The DoesNotReturnIf attribute works the same way, but instead of the method never returning, we can let a bool parameter indicate if the method will return or not. If the value of attribute’s argument matches to value of the associated parameter, it means the method will not return. If we want to use the DoesNotReturnIf attribute, we can refactor our code and use it like this:


Both attributes achieve the same thing and have the same effect, but they are used in slightly different ways and different scenarios.
The last two attributes we need to discuss are MemberNotNull and MemberNotNullWhen. The first one is typically used on methods that are called from a constructor, to let the compiler know which members the method sets. When not assigning a non-nullable member from the constructor, the compiler will give you a warning. Unfortunately, when doing the assignment of a member in a method that gets called from the constructor, the compiler does not track this. By adding the MemberNotNull attribute to a method, we can tell the compiler which fields and properties are being assigned by the method. That way, the compiler knows that after calling this method, the defined properties and/or fields are set. If the developer forgets to assign one of the listed members inside the method, the compiler gives a warning.
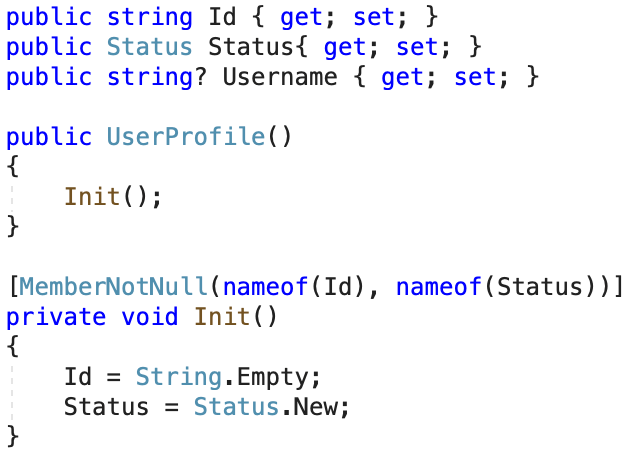
This is very helpful in helper methods that set a particular state on the object.
With the MemberNotNullWhen attribute, we can tell the compiler that when a particular Boolean property or method returns the specified value, the value of another property or field will not be null. This allows us to create helper methods that give back a meaningful bool value about a property’s null state, and after calling the method have the compiler infer the null state of said property in subsequent code.

See how we get a warning on the Rating property when the CheckHasRating method would return false, while we don’t get one when the method returns true. That’s all thanks to the MemberNotNullWhen attribute. This attribute can also be applied to a property of type bool:

In some situations, you might want to (temporarily) opt-out of using NRTs. By adding the ‘#nullable disable’ directive, we can disable the context of the nullable annotation and have our code working like ‘in the old days’ i.e. reference types are nullable and are null by default. That is until the end of the file or until the compiler comes across a ‘#nullable enable’ or ‘#nullable restore’ directive. This can be very handy when copying external code from a blog post or from StackOverflow. Often code found online doesn’t embrace NRTs, and as a result, using that code in your codebase would potentially give a lot of warnings regarding nullability. To bypass these warnings, you might want to surround that code with the earlier-mentioned directives. In an ideal world, after you’ve validated that code, you would want to refactor it, deal with NRTs and remove the directives again.
I hope, after reading this article, you have a good understanding on how to deal with NRTs. It’s a lot to digest, with new concepts to take in, and it requires you as a developer to be attentive to nullability and be more expressive and explicit. Honestly, though, I’ve far from covered everything in this article. I barely scratched the surface. Things like deserialization of objects, integration with Entity Framework, making sure your objects are correct by construction, etc., require special attention! But it’s important to start with the core concepts.
Also be aware that working with NRTs, doesn’t guarantee having no null reference exception anymore. Another developer might use the null-forgiving operator (!) to assign null to a non-nullable member, or pass null where the argument type is non-nullable. At least the developer knows at that moment they’re doing something that will most likely fault the system. And when an exception occurs, it’s their own fault. It’s more subtle when deserializing an object that hasn’t got a value for a non-nullable member. That’s why it is recommended you still do null-checks in some cases. Especially on API endpoints to see whether the posted value is correct in terms of non-nullability.
Personally, I think NRTs is one of the greatest features introduced in the last couple of years in .NET. Despite it having a pretty high threshold to embrace fully, it defiantly makes your code a lot better in many ways, in my opinion. Please do if you have any more questions about NRTs!
Want to learn more? Get in touch!

